English version coming in a few days!
はじめに
codex usage 無理で絶望してる
🚀 ccusage v17.0 リリース! codex対応です!! これでccusageシリーズでccとcodex両方いけます!! コマンドはこちら↓ ``` npx @ccusage/codex bunx @ccusage/codex@latest # ⚠️bunxは@latest必須なことに注意してください。つけ忘れるとcodex本体が起動します ```
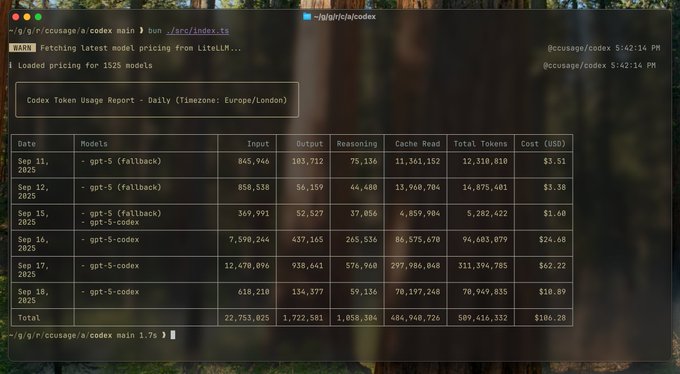
🚀 ccusage v17.0 is here! Now with OpenAI Codex support! Track token usage & costs across Claude Code AND Codex in one CLI. Monitor GPT-5, 1M context windows, and all your AI coding expenses. npx @ccusage/codex bunx @ccusage/codex@latest ⚠️(@latest required for bunx)
ccusage が v17.0.0 にてついに OpenAI Codex の token 使用量追跡をサポートしました!!
🎉🎉
今回は、なぜ Codex サポートが「不可能」から「可能」になったのか、その技術的な背景と実装の詳細について解説します。
ccusage とは?
ccusage とは、言わずと知れた Claude Code の token 使用量、そして本来の API コストを計算し、開発者をニヤニヤさせるための CLI ツールです。
直近では、8K+ の GitHub スター、400K+ のダウンロード数を達成しました!本当にありがとうございます。
Thanks 8K ✨
最初の壁:なぜ Codex サポートは不可能だったのか
Claude Code が5月下旬から大流行し、5月末に ccusage がリリースされ、Claude Code のエコシステムは大いに盛り上がりました。 7月には Gemini CLI が、8月ごろから4月にすでにリリースはされていたものの注目されていなかった OpenAI Codex CLI が GPT-5 のリリースとともに再注目され始めました。
当然、ccusage のユーザーからも Codex サポートの要望が寄せられました。
しかしまあ無理でしょうというのが当時の私の見解でした。
理由はシンプルです:
OpenAI Codex は、token 使用量データを解析可能な形式でログに残していなかった
セッションファイルに token 数の情報が存在しなければ、それをトラッキングすることは不可能です。 もちろん以下のような方法も考えられましたが:
Codex は OSS なので、token 情報を残すように Fork 版を作る
通信をモックして token 情報を得る(これは Node.js 版の時は可能だったが、Rust 版に移行したことで実質不可能になった)
まあ現実的ではないですね。
といいつつも、常にリリースを追いかけてはいました。
転機:2025年9月の OpenAI アップデート
2025年9月、OpenAI は GPT-5-Codex のリリースに向けて、Codex CLI の大幅なアップデートを行いました。このアップデートこそが、ccusage にとってのゲームチェンジャーとなったのです。
変更1:構造化された token 使用量データの追加(9月6日)
// Before: token 情報が不明瞭
EventMsg::TokenCount { ... }
// After: 構造化された TokenCountEvent
TokenCountEvent {
input_tokens: u32,
cached_input_tokens: u32,
output_tokens: u32,
reasoning_output_tokens: u32,
total_tokens: u32,
}コミット 0269096 により、payload に構造化された token 使用量データが追加されました。
この変更は「コンテキスト情報をメインループに移動して、ループの中断や自動圧縮の開始に使えるようにする」という目的で実装されたものでしたが、結果的に ccusage にとって必要不可欠な情報提供につながりました。
変更2:JSONL 形式でのセッション永続化(9月9日)
# セッションファイルの保存先
$CODEX_HOME/sessions/**.jsonlコミット 43809a4 により、EventMsg::TokenCount エントリが JSONL ファイルとして永続化されるようになりました。
これで、ついに token 使用量データがアーカイブされ、アクセス可能になったのです!
この時点ですでに token 使用量を解析し、モデルを gpt-5 としてコスト計算を行うことが可能でした。
自分はちょうど仕事のタイミングで忙しく、やりたいなと思いつつ手がつけられずもどかしく思っていました。
実際この直後に cxusage という CLI がリリースされていました。
変更3:モデルメタデータの追加(9月11日)
{
"type": "turn_context",
"model": "gpt-5-codex",
"timestamp": "2025-09-15T12:34:56Z"
}コミット 674e3d3 により、各ターンでモデル情報が記録されるようになりました。
GPT-5-Codex リリース
これらの変更は偶然ではありません。2025年9月15日の GPT-5-Codex 正式リリースに向けた準備の一環でした。
OpenAI は新モデルの運用に必要なロギングインフラを整備し、その副産物として ccusage が必要としていたデータへのアクセスが可能になったのです。
ccusage v17.0.0 の実装
あとは Claude Code の時にやってきたものを Codex に移植するだけです。
// JSONL パーサーの実装(簡略化)
export async function parseCodexSession(sessionPath: string) {
const lines = await readLines(sessionPath);
return lines
.map(line => JSON.parse(line))
.filter(entry => entry.type === 'TokenCount')
.map(entry => ({
inputTokens: entry.input_tokens,
outputTokens: entry.output_tokens,
cachedTokens: entry.cached_input_tokens,
reasoningTokens: entry.reasoning_output_tokens,
model: extractModel(entry),
}));
}主な実装ポイント:
$CODEX_HOME/sessions/配下の JSONL ファイルを解析token 使用量を抽出
turn_contextエントリから使用モデルを特定token 数とmodelの価格を付き合わせてコスト計算
技術的な課題
今回は新しいコマンドをリリースしたので、repository の構成を monorepo 化しました。これが本当に大変でした。
また、bun では monorepo で package を開発して publish するのにはまだまだ役不足であったので、pnpm + catalogue への移行も行いました。
さらに、ccusage 本体の bundle size を減らすために、MCP 機能を @ccusage/mcp という別 package に切り出し、zod -> valibot への移行も行いました(結果 1MB -> 600KB に削減)。
これを3日くらいかけてやりました。まじで大変だった。
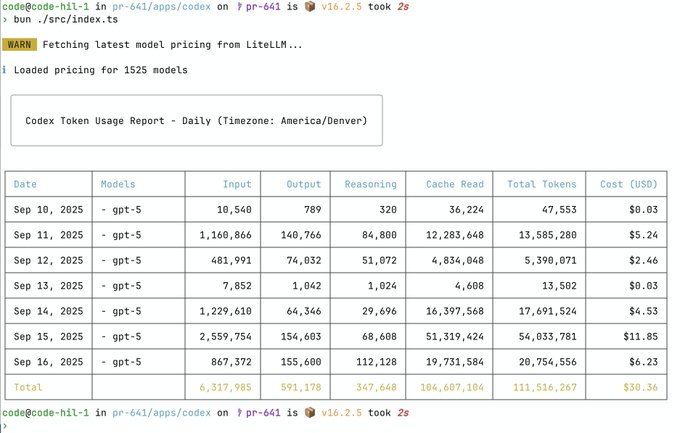
加えて、Codex 向けの計算が正しいかどうかコミッターの Ben と何度もやりとりをしました。いつもありがとうございます。
Looking good - I need to step up my use... it's so much cheaper than Claude!!
まとめ

ccusage v17.0.0 は GitHub で公開中です。ぜひお試しください!
bunx ccusage@latest --help
bunx @ccusage/codex@latest --help
bunx @ccusage/mcp@latest --helpスポンサー大募集!
スポンサーを募集しています!ccusage 面白い!とかもっと OSS を開発してほしい!と思った方は是非ともスポンサーになってください!(特に ccusage の開発は基本的には無給かつボランティアです!)
いつも応援してくださる方には本当に感謝しています。これ以外にも Vibe Coding や開発のための OSS を開発しているので是非ともサポートをお願いします!
(いただいたスポンサーのうち、一部は ccusage の contributor に再分配しています)
